Word2Vec
#deepLearning/word2vec
预训练
预训练的思想:任务 A 对应的模型 A 的参数不再是随机初始化的,而是通过任务 B 进行预先训练得到模型 B,然后利用模型 B 的参数对模型 A 进行初始化,再通过任务 A 的数据对模型 A 进行训练。注:模型 B 的参数是随机初始化的。
语言模型
语言模型通俗点讲就是计算一个句子的概率。也就是说,对于语言序列 $w_1,w_2,\cdots,w_n$,语言模型就是计算该序列的概率,即 $P(w_1,w_2,\cdots,w_n)$。
下面通过两个实例具体了解上述所描述的意思:
- 假设给定两句话 “判断这个词的磁性” 和 “判断这个词的词性” ,语言模型会认为后者更自然。转化成数学语言也就是:$$P(判断,这个,词,的,词性) \gt P(判断,这个,词,的,磁性)$$
- 假设给定一句话做填空 “判断这个词的__“,则问题就变成了给定前面的词,找出后面的一个词是什么,转化成数学语言就是:$$P(词性|判断,这个,词,的) \gt P(磁性|判断,这个,词,的)$$
通过上述两个实例,可以给出语言模型更加具体的描述:给定一句由 $n$ 个词组成的句子 $W=w_1,w_2,\cdots,w_n$,计算这个句子的概率 $P(w_1,w_2,\cdots,w_n)$,或者计算根据上文计算下一个词的概率 $P(w_n|w_1,w_2,\cdots,w_{n-1})$。
下面将介绍语言模型的两个分支,统计语言模型和神经网络语言模型。
统计语言模型
统计语言模型的基本思想就是计算条件概率。
给定一句由 $n$ 个词组成的句子 $W=w_1,w_2,\cdots,w_n$,计算这个句子的概率 $P(w_1,w_2,\cdots,w_n)$ 的公式如下(条件概率乘法公式的推广,链式法则):
$$
\begin{align*}
P(w_1, w_2, \cdots, w_n) &= P(w_1) \cdot P(w_2 \mid w_1) \cdot P(w_3 \mid w_1, w_2) \cdots P(w_n \mid w_1, w_2, \cdots, w_{n-1}) \
&= \prod_{i=1}^{n} P(w_i \mid w_1, w_2, \cdots, w_{i-1})
\end{align*}
$$
对于上一节提到的 “判断这个词的词性” 这句话,利用上述的公式,可以得到:
$$
\begin{align*}
& P(判断,这个,词,的,词性) = \
& P(判断)P(这个|判断)P(词|判断,这个) \
& P(的|判断,这个,词)P(词性|判断,这个,词,的)P(判断,这个,词,的,词性)
\end{align*}
$$
对于上一节提到的另外一个问题,当给定前面词的序列 “判断,这个,词,的” 时,想要知道下一个词是什么,可以直接计算如下概率:
$$P(w_{next}|判断,这个,词,的)$$
其中,$w_{next} \in V$表示词序列的下一个词,$V$ 是一个具有 $|V|$ 个词的词典(词集合)。
对于公式(3),可以展开成如下形式:
$$P(w_{next}|判断,这个,词,的) = \frac{count(w_{next},判断,这个,词,的)}{count(判断,这个,词,的)}$$
对于公式(4),可以把字典 $V$ 中的多有单词,逐一作为 $w_{next}$,带入计算,最后取最大概率的词作为 $w_{next}$ 的候选词。
如果 $|V|$ 特别大,公式(4)的计算将会非常困难,但是我们可以引入马尔科夫链的概念(当然,在这里只是简单讲讲如何做,关于马尔科夫链的数学理论知识可以自行查看其他参考资料)。
假设字典 V 中有 “火星” 一词,可以明显发现 “火星” 不可能出现在 “判断这个词的” 后面,因此(火星,判断,这个,词,的)这个组合是不存在的,并且词典中会存在很多类似于 “火星” 这样的词。
进一步,可以发现我们把(火星,判断,这个,词,的)这个组合判断为不存在,是因为 “火星” 不可能出现在 “词的” 后面,也就是说我们可以考虑是否把公式(3)转化为
$$
P(w_{next}|判断,这个,词,的) \approx P(w_{next}|词,的)
$$
公式(5)就是马尔科夫链的思想:假设 $w_{next}$ 只和它之前的 k 个词有相关性,$k=1$ 时称作一个单元语言模型,$k=2$ 时称为二元语言模型。
可以发现通过马尔科夫链后改写的公式计算起来将会简单很多,下面我们举个简单的例子介绍下如何计算一个二元语言模型的概率。
其中二元语言模型的公式为:
$$P(w_i|w_{i-1})=\frac{count(w_{i-1},w_i)}{count(w_{i-1})}$$
假设有一个文本集合:
“词性是动词” |
对于上述文本,如果要计算 P(词性|的) 的概率,通过公式(6),需要统计 “的,词性” 同时按序出现的次数,再除以 “的” 出现的次数:
$$
P(词性|的) = \frac{count(的,词性)}{count(的)} = \frac{2}{3}
$$
上述文本集合是我们自定制的,然而对于绝大多数具有现实意义的文本,会出现数据稀疏的情况,例如训练时未出现,测试时出现了的未登录单词。
由于数据稀疏问题,则会出现概率值为 0 的情况(填空题将无法从词典中选择一个词填入),为了避免 0 值的出现,会使用一种平滑的策略——分子和分母都加入一个非 0 正数,例如可以把公式(6)改为:
$$
P(w_i|w_{i-1}) = \frac{count(w_{i-1},w_i)+1}{count(w_{i-1})+|V|}
$$
独热编码(one-hot)
假设我们现在有单词数量为$𝑁$的词表,那可以生成一个长度为$𝑁$的向量来表示一个单词,在这个向量中该单词对应的位置数值为1,其余单词对应的位置数值全部为0。
词典: [queen, king, man, woman, boy, girl]
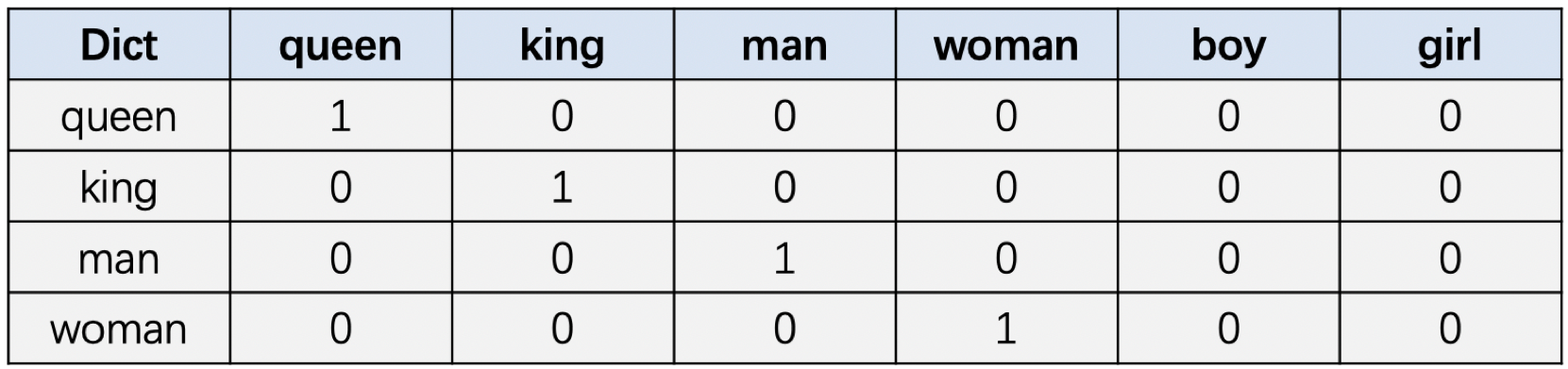
假设当前词典中有以上6个单词,图总展示了其中4个单词的one-hot编码表示。
缺点
在one-hot编码中,每个单词被表示为一个很长的向量,这个向量的维度等于词汇表的大小,向量中只有一个元素是1(表示该单词),其余元素都是0。这种表示方法虽然简单,但是它无法捕捉单词之间的关系,而且随着词汇表的增大,向量的维度也会大幅增加,导致计算效率低下。
Word Embedding
单独的one-hot仅仅只代表了一个无意义的编码。通过词嵌入的方式,使得此单词可以被更多维度的特征所描述,而这些特征是在一个连续的向量空间中表示的。
word embedding将每个单词表示为一个固定长度的稠密向量,语义相近的单词之间的距离在向量空间中会比较近,语义不同的单词之间距离会比较远。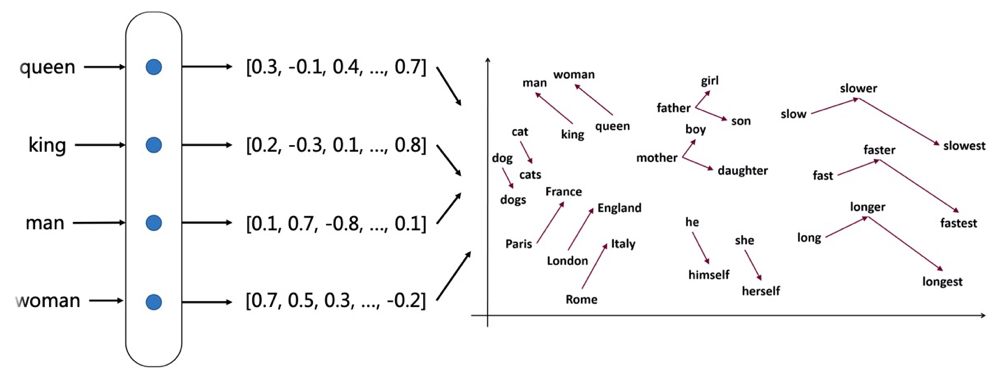
可以看到France, England, Italy等国家之间比较近,并形成一个小簇;dog, dogs,cat,cats形成一个小簇。
Word2Vec
Word2Vec是建模了一个单词预测的任务,通过这个任务来学习词向量。假设有这样一句话Pineapples are spiked and yellow,现在假设spiked这个单词被删掉了,现在要预测这个位置原本的单词是什么。
Word2Vec本身就是在建模这个单词预测任务,当这个单词预测任务训练完成之后,那每个单词对应的词向量也就训练好了。
Word2vec是2013年被Mikolov提出来的词向量训练算法,在论文中作者提到了两种word2vec的具体实现方式:连续词袋模型CBOW和Skip-gram:
CBOW(Continuous Bag of Words): 根据上下文预测当前单词
Skip-gram: 根据当前单词预测上下文
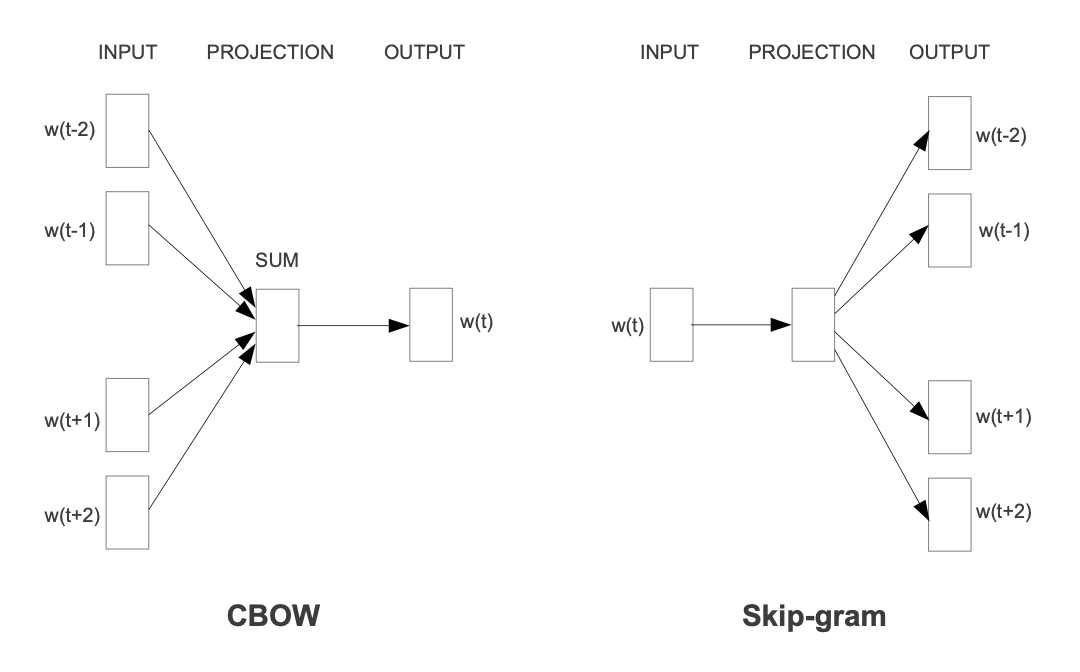
一般来说,CBOW比Skip-garm训练快且更加稳定一些,然而,Skip-garm不会刻意地回避生僻词(即出现频率比较低的词),比CBOW能够更好地处理生僻词。
Skip-gram
前边说到,Skip-gram是通过中心词来预测上下文。以Pineapples are spiked and yellow为例进行讲解,如图所示,中心词是spiked,上下文是Pineapples are and yellow,在Skip-gram中,上下文是我们要预测的词,因此这些词也叫目标词。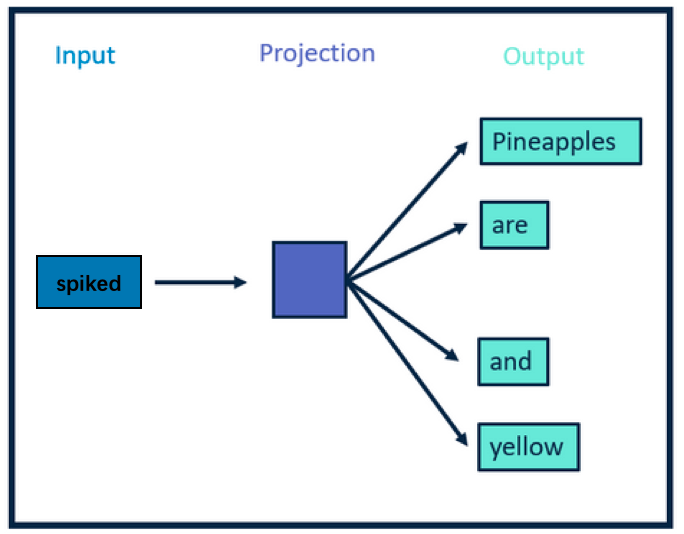
Skip-gram网络结构
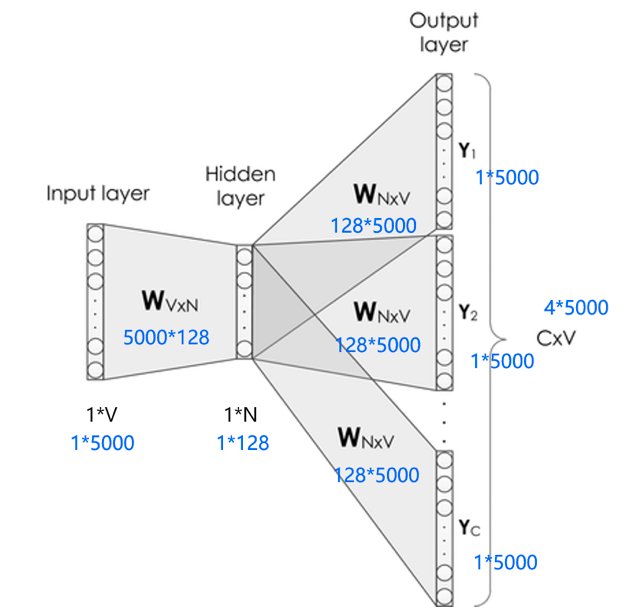
Skip-gram的网络结构共包含三层:输入层,隐藏层和输出层。它的处理步骤是这样的:
输入层接收shape为 $[1,V]$ 的 $one-hot$ 向量 $x$,其中 $V$ 代表词表中单词的数量,这个 $one-hot$ 向量就是上边提到的中心词。
隐藏层包含一个shape为 $[V,N]$ 的参数矩阵 $W_1$,其中这个 $N$ 代表词向量的维度,$W_1$ 就是word embedding 矩阵,即我们要学习的词向量。将输入的 $one-hot$ 向量 $x$ 与 $W_1$ 相乘,便可得到一个shape为 $[1, N]$ 的向量,即该输入单词对应的词向量 $e$。
输出层包含一个shape为 $[N,V]$ 的参数矩阵 $W_2$,将隐藏层输出的 $e$ 与 $W_2$ 相乘,便可以得到shape为 $[1,V]$ 的向量 $r$,内部的数值分别代表每个候选词的打分,使用softmax函数,对这些打分进行归一化,即得到中心词的预测各个单词的概率。
这是一种比较理想的实现方式,但是这里有两个问题:
这个输入向量是个one-hot编码的方式,只有一个元素为1,其他全是0,是个极其稀疏的向量,假设它第2个位置为1,它和word embedding相乘,便可获得word embedding矩阵的第二行的数据。那么我们知道这个规律,直接通过访存的方式直接获取就可以了,不需要进行矩阵相乘。
在获取了输入单词对应的词向量 $e$ 后,它是一个 $[1,N]$ 向量。接下来,会使用这个向量和另外一个大的矩阵 $W_2$ 进行相乘,最终会获得一个 $1*V$ 的向量,然后对这个向量进行softmax,可以看到这个向量具有词表的长度,对这么长的向量进行softmax本身也是一个极其消耗资源的事情。
负采样解决大规模分类问题
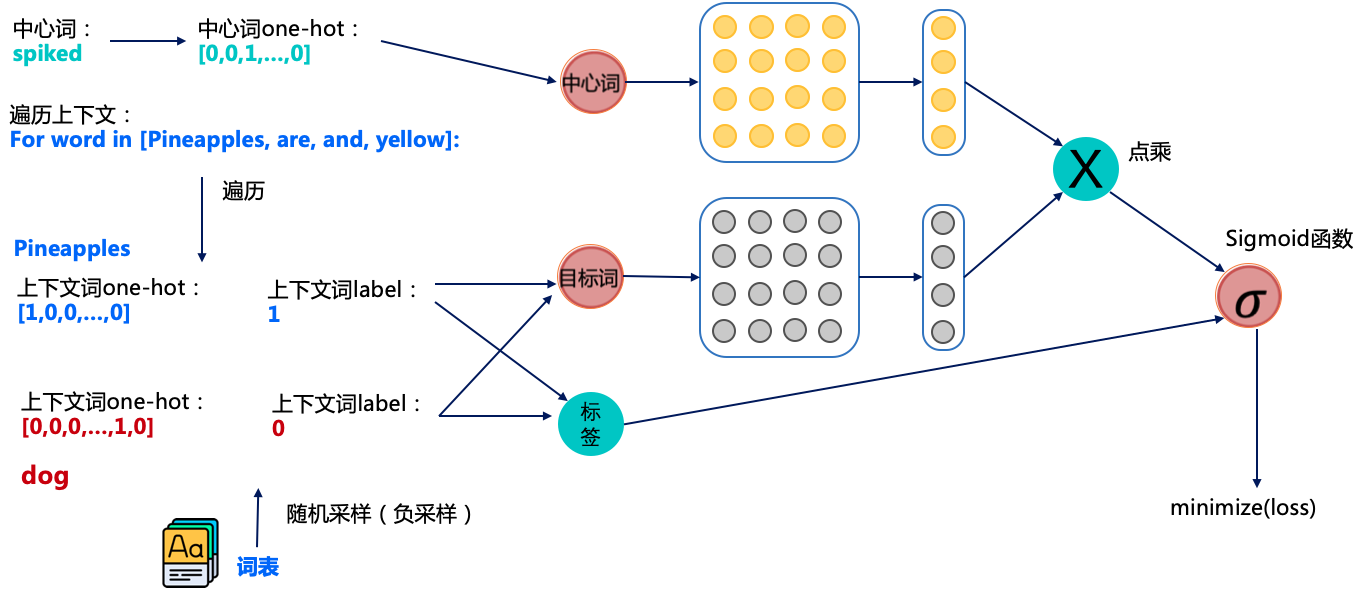
如图所示,其中中心词是spiked和上下文词是正样本Pineapples are and yellow,这里这个正样本代表该词是中心词的上下文。
以正样本单词Pineapples为例,之前的做法是在使用softmax学习时,需要最大化Pineapples的推理概率,同时最小化其他词表中词的推理概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。
例如,先指定一个中心词(spiked)和一个目标词正样本(Pineapples),再随机在词表中采样几个目标词负样本(如dog,house等)。
有了这些正负样本,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。这个做法就是负采样。
我们再回到图7看一看整体的训练流程是怎么样的。图7中相当于有两个词向量矩阵:黄色的和灰色的,他们的shape都是一样的。整体的流程大概是这样的。
获取中心词spiked的正负样本(正负样本是目标词),这里一般会设定个固定的窗口,比如中心词前后3个词算是中心词的上下文(即正样本);
获取对应词的词向量,其中中心词从黄色的向量矩阵中获取词向量,目标词从灰色的向量矩阵中获取词向量。
将中心词和目标词的词向量进行点积并经过sigmoid函数,我们知道sigmoid是可以用于2分类的函数,通过这种方式来预测中心词和目标词是否具有上下文关系。
将预测的结果和标签使用交叉熵计算损失值,并计算梯度进行反向迭代,优化参数。
经过这个训练的方式,我们就可以训练出我们想要的词向量,但图7中包含两个词向量矩阵(黄色的和灰色的),一般是将中心词对应的词向量矩阵(黄色的)作为正式训练出的词向量。
RNN
传统的神经网络无法获取时序信息,然而时序信息在自然语言处理任务中非常重要。
例如对于这一句话 “我吃了一个苹果”,“苹果” 的词性和意思,在这里取决于前面词的信息,如果没有 “我吃了一个” 这些词,“苹果” 也可以翻译为乔布斯搞出来的那个被咬了一口的苹果。
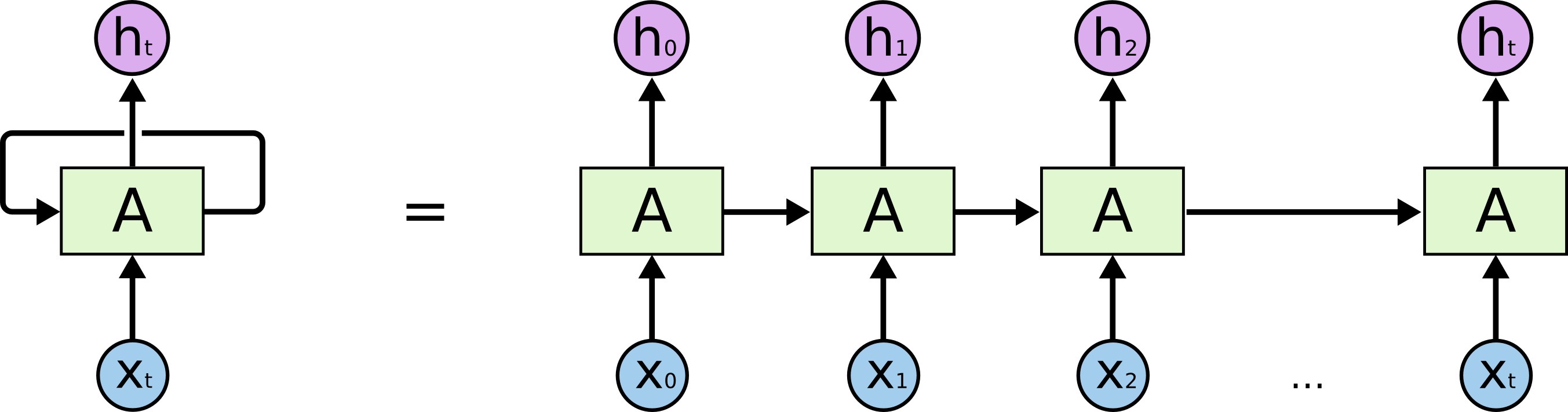
上图左边部分称作 RNN 的一个 timestep,在这个 timestep 中可以看到,在 𝑡 时刻,输入变量 $x_t$,通过 RNN 的一个基础模块 A,输出变量 $h_t$,而 $t$ 时刻的信息,将会传递到下一个时刻 $t+1$。
如果把模块按照时序展开,则会如上图右边部分所示,由此可以看到 RNN 为多个基础模块 A 的互连,每一个模块都会把当前信息传递给下一个模块。
RNN 解决了时序依赖问题,但这里的时序一般指的是短距离的,短距离依赖和长距离依赖的区别:
- 短距离依赖:对于这个填空题 “我想看一场篮球___”,我们很容易就判断出 “篮球” 后面跟的是 “比赛”,这种短距离依赖问题非常适合 RNN。
- 长距离依赖:对于这个填空题 “我出生在中国的瓷都景德镇,小学和中学离家都很近,……,我的母语是___”,对于短距离依赖,“我的母语是” 后面可以紧跟着 “汉语”、“英语”、“法语”,但是如果我们想精确答案,则必须回到上文中很长距离之前的表述 “我出生在中国的瓷都景德镇”,进而判断答案为 “汉语”,而 RNN 是很难学习到这些信息的。
LSTM
为了解决 RNN 缺乏的序列长距离依赖问题,LSTM 被提了出来,首先来看 LSTM 相对于 RNN 做了哪些改进: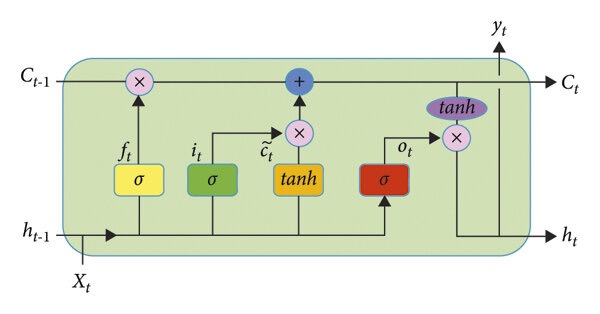
如上图所示,LSTM 的 RNN 门控结构(LSTM 的 timestep),LSTM 前向传播过程包括:
- 遗忘门:决定了丢弃哪些信息,遗忘门接收 $t-1$ 时刻的状态 $h_{t-1}$,以及当前的输入 $x_t$,经过 Sigmoid 函数后输出一个 0 到 1 之间的值 $f_t$
- 输出: $f_{t} = \sigma(W_fh_{t-1} + U_fx_{t} + b_f)$
- 输入门:决定了哪些新信息被保留,并更新细胞状态,输入门的取值由 $h_{t-1}$ 和 $x_t$ 决定,通过 Sigmoid 函数得到一个 0 到 1 之间的值 $i_t$,而 $\tanh$ 函数则创造了一个当前细胞状态的候选 $a_t$
- 输出:$i_{t} = \sigma(W_ih_{t-1} + U_ix_{t} + b_i) , \tilde{C_{t} }= tanhW_ah_{t-1} + U_ax_{t} + b_a$
- 细胞状态:旧细胞状态 $C_{t-1}$ 被更新到新的细胞状态 $C_t$ 上,
- 输出:$C_{t} = C_{t-1}\odot f_{t} + i_{t}\odot \tilde{C_{t} }$
- 输出门:决定了最后输出的信息,输出门取值由 $h_{t-1}$ 和 $x_t$ 决定,通过 Sigmoid 函数得到一个 0 到 1 之间的值 $o_t$,最后通过 $\tanh$ 函数决定最后输出的信息
- 输出:$o_{t} = \sigma(W_oh_{t-1} + U_ox_{t} + b_o) , h_{t} = o_{t}\odot tanhC_{t}$
- 预测输出:$\hat{y}{t} = \sigma(Vh{t}+c)$
BERT
BERT 全称为 Bidirectional Encoder Representations from Transformers(来自 Transformers 的双向编码器表示),是谷歌发表的论文 Pre-training of Deep Bidirectional Transformers for Language Understanding 中提出的一个面向自然语言处理任务的无监督预训练语言模型,是近年来自然语言处理领域公认的里程碑模型。
- BERT 的意义在于:从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
- BERT 被认为是近年来优秀预训练语言模型的集大成者,其参考了 ELMo 模型的双向编码思想,借鉴了 GPT 用 Transformer 作为特征提取器的思路,并采用了 word2vec 所使用的 CBOW 训练方法。
- 单向编码和双向编码的差异,例如 “今天天气很{},我们不得不取消户外运动”,分别从单向编码和双向编码的角度去考虑 {} 中应该填什么词:
- 单向编码:单向编码只会考虑 “今天天气很”,以人类的经验,大概率会从 “好”、“不错”、“差”、“糟糕” 这几个词中选择,这些词可以被划为截然不同的两类
- 双向编码:双向编码会同时考虑上下文的信息,即除了会考虑 “今天天气很” 这五个字,还会考虑 “我们不得不取消户外运动” 来帮助模型判断,则大概率会从 “差”、“糟糕” 这一类词中选择
- 不考虑模型的复杂度和训练数据量,双向编码与单向编码相比,可以利用更多的上下文信息来辅助当前词的语义判断。在语义理解能力上,采用双向编码的方式是最科学的,而BERT 的成功很大程度上由此决定。
NSP(Next Sentence Prediction)
处理两个句子之间的关系
NSP 的具体做法是,BERT 输入的语句将由两个句子构成,其中,50% 的概率将语义连贯的两个连续句子作为训练文本(连续句对一般选自篇章级别的语料,以此确保前后语句的语义强相关),另外 50% 的概率将完全随机抽取两个句子作为训练文本。
连续句对:[CLS]今天天气很糟糕[SEP]下午的体育课取消了[SEP] |
[SEP]: nsp二分类中采用一个符号sep对两个句子进行一个隔断区分
[CLS]: 训练时,将 CLS 的输出向量接一个二分类器来做二分类任务
结果为 1,表示输入为连续句对;结果为 0,表示输入为随机句对。
通过训练 [CLS] 编码后的输出标签,BERT 可以学会捕捉两个输入句对的文本语义,在连续句对的预测任务中,BERT 的正确率可以达到 97%-98%。
MLM(Masked Language Model)
基本原理是将输入句子中的某些单词随机掩盖(即用一个特殊的标记替换),然后让模型预测被掩盖的单词是什么。
- 随机把一些子词用 Mask 代替
- 让模型去预测被 Mask 代替的子词
例如: ["<CLS>", "my", "dog", "is", "cute", "<SEP>", "he", "likes", "play", "##ing", "<SEP>"]
变为: ["<CLS>", "my", "<mask>", "is", "dog", "<SEP>", "he", "likes", "play", "<mask>", "<SEP>"]
随机去掉的 token 被称作掩码词,在训练中,掩码词将以 15% 的概率被替换成 [MASK],这个操作则称为掩码操作。注意:在CBOW 模型中,每个词都会被预测一遍。
但是这样设计 MLM 的训练方法会引入弊端:在模型微调训练阶段或模型推理(测试)阶段,输入的文本中将没有 [MASK],进而导致产生由训练和预测数据偏差导致的性能损失。
考虑到上述的弊端,BERT 并没有总用 [MASK] 替换掩码词,而是按照一定比例选取替换词。在选择 15% 的词作为掩码词后这些掩码词有三类替换选项:
- 80% 的训练样本中:将选中的词用 [MASK] 来代替,例如:
“地球是[MASK]八大行星之一”
- 10% 的训练样本中:选中的词不发生变化,该做法是为了缓解训练文本和预测文本的偏差带来的性能损失,例如:
“地球是太阳系八大行星之一”
- 10% 的训练样本中:将选中的词用任意的词来进行代替,该做法是为了让 BERT 学会根据上下文信息自动纠错,例如:
“地球是苹果八大行星之一”
Mask代码
for mlm_pred_position in candidate_pred_positions: |
输入表示
Bert 使用多个 encoder 堆叠在一起,其中 bert base 使用的是 12 层的 encoder,bert large 使用的是 24 层的 encoder。
由于 BERT 通过 Transformer 模型堆叠而成,所以 BERT 的输入需要两套 Embedding 操作:
- 一套为 One-hot 词表映射编码(Token Embeddings),在BERT中,One-hot 编码向量通过嵌入矩阵转换为密集的词嵌入向量。嵌入矩阵是一个学习参数矩阵,表示词汇表中的每个词汇的向量表示。通过预训练,这些向量能够捕捉到词汇的语义和上下文关系。
- 另一套为位置编码(Position Embeddings),不同于 Transformer 的位置编码用三角函数表示,BERT 的位置编码将在预训练过程中训练得到(训练思想类似于Word Embedding 的 Q 矩阵)
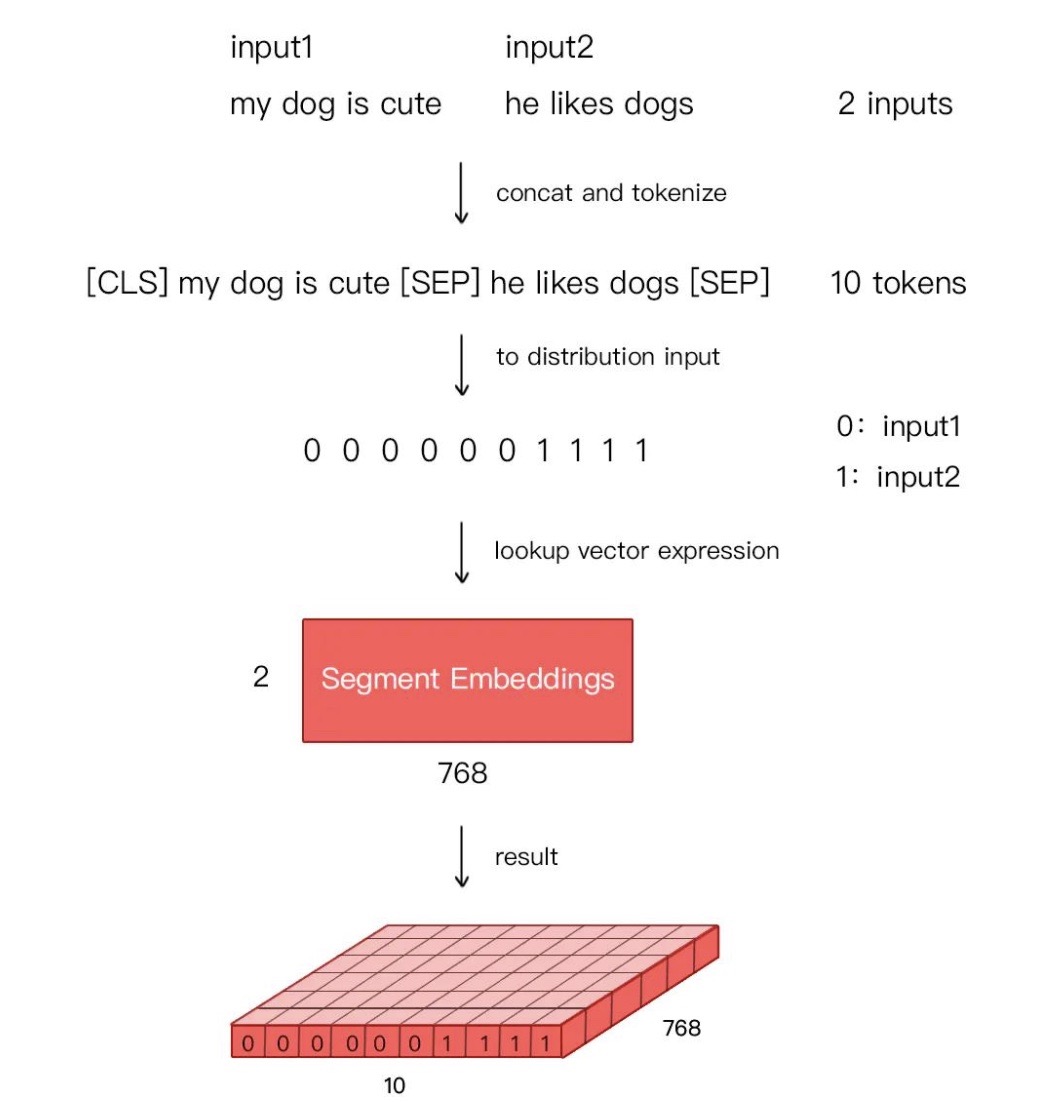
- 由于在 MLM 的训练过程中,存在单句输入和双句输入的情况,因此 BERT 还需要一套区分输入语句的分割编码(Segment Embeddings),BERT 的分割编码也将在预训练过程中训练得到
$\text{Input Representation} = \text{Token Embeddings} + \text{Position Embeddings} + \text{Segment Embeddings}$
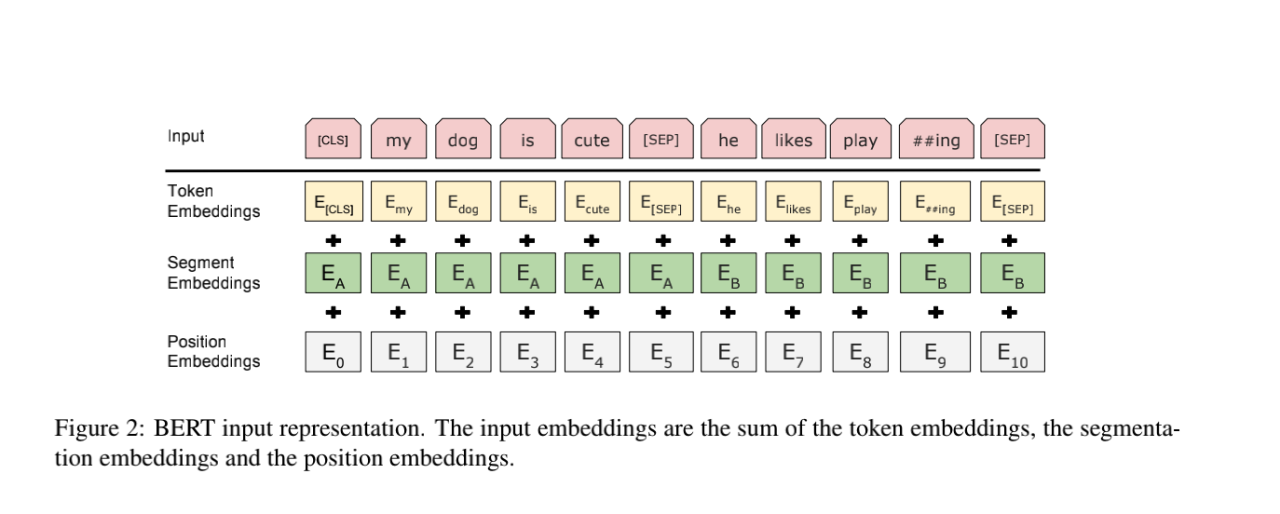
对于分割编码,Segment Embeddings 层只有两种向量表示。前一个向量 $E_A$ 是把 0 赋给第一个句子中的各个 token,后一个向量 $E_B$ 是把 1 赋给第二个句子中的各个 token ;如果输入仅仅只有一个句子,那么它的 segment embedding 就是全 0,下面我们简单举个例子描述下:
[CLS]I like dogs[SEP]I like cats[SEP] 对应编码 0 0 0 0 0 1 1 1 1 |
BERT 适应下游任务
BERT 根据自然语言处理下游任务的输入和输出的形式,将微调训练支持的任务分为四类,分别是句对分类、单句分类、文本问答和单句标注。
句对分类
给定两个句子,判断它们的关系,称为句对分类,例如判断句对是否相似、判断后者是否为前者的答案。
针对句对分类任务,BERT 在预训练过程中就使用了 NSP 训练方法获得了直接捕获句对语义关系的能力。
针对二分类任务,BERT 不需要对输入数据和输出数据的结构做任何改动,直接使用与 NSP 训练方法一样的输入和输出结构就行。
句对用 [SEP] 分隔符拼接成文本序列,在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。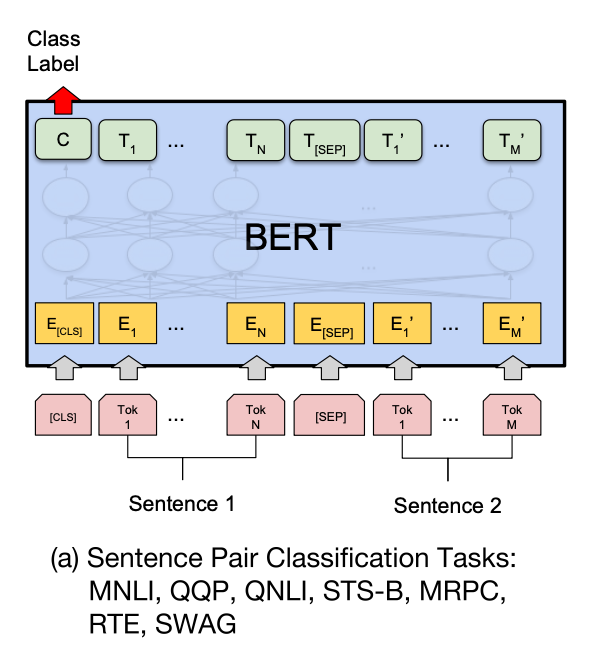
针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 arg max 操作(取最大值时对应的索引序号)得到相对应的类别结果。
任务:判断句子 “我很喜欢你” 和句子 “我很中意你” 是否相似 |
单句分类
给定一个句子,判断该句子的类别,统称为单句分类,例如判断情感类别、判断是否为语义连贯的句子。
针对单句二分类任务,也无须对 BERT 的输入数据和输出数据的结构做任何改动。
单句分类在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。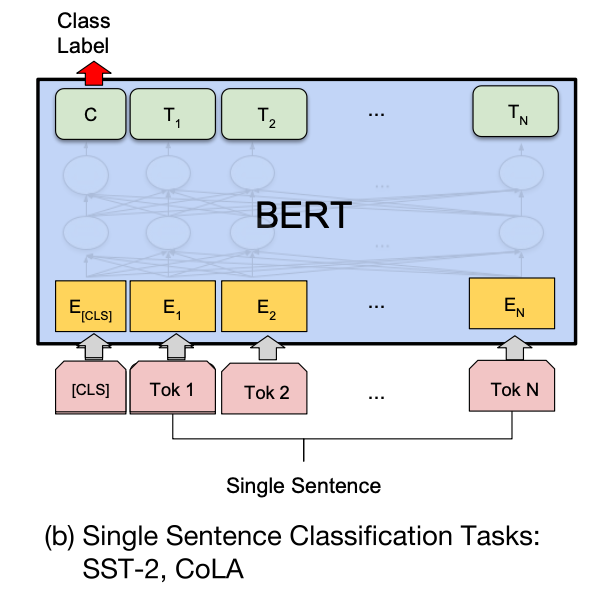
同样,针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 argmax 操作得到相对应的类别结果。
任务:判断句子“海大球星饭茶吃” 是否为一句话 |
文本问答
给定一个问句和一个蕴含答案的句子,找出答案在后者中的位置,称为文本问答,例如给定一个问题(句子 A),在给定的段落(句子 B)中标注答案的起始位置和终止位置。
文本问答任何和前面讲的其他任务有较大的差别,无论是在优化目标上,还是在输入数据和输出数据的形式上,都需要做一些特殊的处理。
为了标注答案的起始位置和终止位置,BERT 引入两个辅助向量 $s$(start,判断答案的起始位置) 和 $e$(end,判断答案的终止位置)。
BERT 判断句子 B 中答案位置的做法是,将句子 B 中的每一个词得到的最终特征向量 $T_i’$ 经过全连接层(利用全连接层将词的抽象语义特征转化为任务指向的特征)后,分别与向量 $s$ 和 $e$ 求内积,对所有内积分别进行 softmax 操作,即可得到词 Tok $m(m\in [1,M])$作为答案起始位置和终止位置的概率。最后,取概率最大的片段作为最终的答案。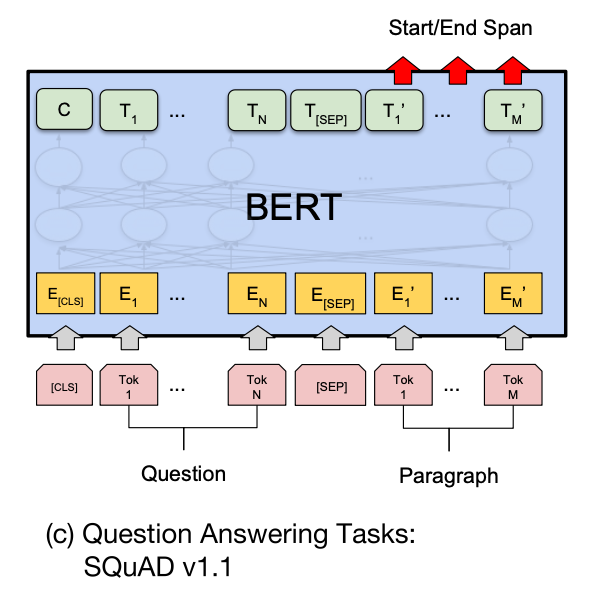
文本回答任务的微调训练使用了两个技巧:
- 用全连接层把 BERT 提取后的深层特征向量转化为用于判断答案位置的特征向量
- 引入辅助向量 $s$ 和 $e$ 作为答案起始位置和终止位置的基准向量,明确优化目标的方向和度量方法
任务:给定问句 “今天的最高温度是多少”,在文本 “天气预报显示今天最高温度 37 摄氏度” 中标注答案的起始位置和终止位置。
输入改写:“[CLS]今天的最高温度是多少[SEP]天气预报显示今天最高温度 37 摄氏度”
BERT Softmax 结果:
篇章文本 天气 预报 显示 今天 最高温度 37 摄氏度 起始位置概率 0.01 0.01 0.01 0.04 0.10 0.80 0.03 终止位置概率 0.01 0.01 0.01 0.03 0.04 0.10 0.80 对 Softmax 的结果取
arg max,得到答案的起始位置为 6,终止位置为 7,即答案为 “37 摄氏度”。
单句标注
给定一个句子,标注每个词的标签,称为单句标注。例如给定一个句子,标注句子中的人名、地名和机构名。
单句标注任务和 BERT 预训练任务具有较大差异,但与文本问答任务较为相似。
在进行单句标注任务时,需要在每个词的最终语义特征向量之后添加全连接层,将语义特征转化为序列标注任务所需的特征,单句标注任务需要对每个词都做标注,因此不需要引入辅助向量,直接对经过全连接层后的结果做 Softmax 操作,即可得到各类标签的概率分布。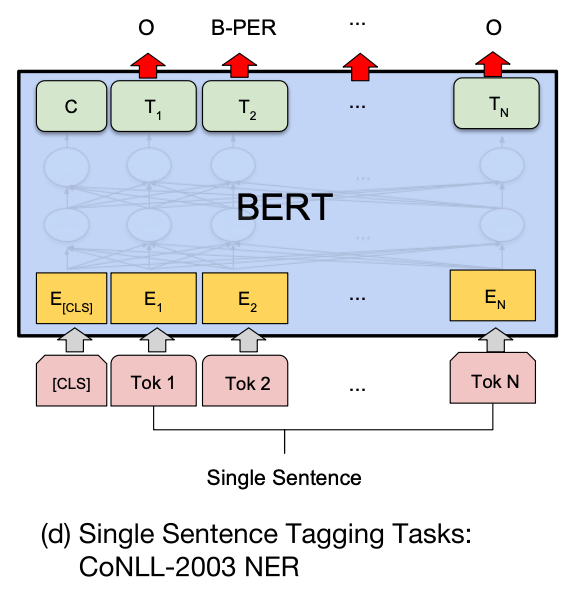
由于 BERT 需要对输入文本进行分词操作,独立词将会被分成若干子词,因此 BERT 预测的结果将会是 5 类(细分为 13 小类):
- O(非人名地名机构名,O 表示 Other)
- B-PER/LOC/ORG(人名/地名/机构名初始单词,B 表示 Begin)
- I-PER/LOC/ORG(人名/地名/机构名中间单词,I 表示 Intermediate)
- E-PER/LOC/ORG(人名/地名/机构名终止单词,E 表示 End)
- S-PER/LOC/ORG(人名/地名/机构名独立单词,S 表示 Single)
将 5 大类的首字母结合,可得 IOBES,这是序列标注最常用的标注方法。
下面给出命名实体识别(NER)任务的示例:
任务:给定句子 “爱因斯坦在柏林发表演讲”,根据 IOBES 标注 NER 结果
输入改写:“[CLS]爱 因 斯 坦 在 柏 林 发 表 演 讲”
BERT Softmax 结果:
BOBES 爱 因 斯坦 在 柏林 发表 演讲 O 0.01 0.01 0.01 0.90 0.01 0.90 0.90 B-PER 0.90 0.01 0.01 0.01 0.01 0.01 0.01 I-PER 0.01 0.90 0.01 0.01 0.01 0.01 0.01 E-PER 0.01 0.01 0.90 0.01 0.90 0.01 0.01 S-LOC 0.01 0.01 0.01 0.01 0.01 0.01 0.01 对 Softmax 的结果取 arg max,得到最终地 NER 标注结果为:“爱因斯坦” 是人名;“柏林” 是地名