#back-end/mysql
MySQL 启动myslq
初始化MySQL mysql_secure_installation
往下一直Y 直到人家谢谢你 初始化完成
Thanks for using MariaDB!
登录MySQL 这里密码为空,直接回车就可登入
创建数据库 这里是root用户,可以使用mysqladmin来创建database
mysqladmin -u root -p create tutorials
create database tutorials
创建完成后show databases
MariaDB [mysql]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | joeybase | | joeychamber | | mysql | | performance_ schema || turorials | +--------------------+ 6 rows in set (0.000 sec)
使用root登录后
CREATE DATABASE IF NOT EXISTS SPACE DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
该命令的作用
如果数据库不存在则创建,存在则不创建
创建SPACE数据库,并设定编码集为utf8
删除数据库 mysqladmin -u root -p drop joeychamber
再来show一遍
MariaDB [mysql]> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | joeybase | | mysql | | performance_schema | | turorials | +--------------------+ 5 rows in set (0.000 sec)
FLOAT和DOUBLE差异 (单精度与双精度有什么区别)
最本质的区别:
单精度(float )在 32 位机器上用4 个字节来存储的 双精度(double )是用8 个字节来存储的,由于存储位不同,他们能表示的数值的范围就不同,也就是能准确表示的数的位数就不同
1、所占的内存不同
单精度浮点数占用4个字节(32位)存储空间来存储一个浮点数,包括符号位1位,阶码8位,尾数23位 而双精度浮点数使用 8个字节(64位)存储空间来存储一个浮点数,包括符号位1位,阶码11位,尾数52位
2、所存的数值范围不同
单精度浮点数的数值范围为-3.4E38~3 .4 E38,而双精度浮点数可以表示的数字的绝对值范围大约是:-2.23E308 ~ 1.79E308 E表示10 的多少次方,如3 .4 E38指的是3 .4 乘以10 的38 次方
3、十进制下的位数不同
单精度浮点数最多有7位十进制有效数字,如果某个数的有效数字位数超过7位,当把它定义为单精度变量时,超出的部分会自动四舍五入 双精度浮点数可以表示十进制的15或16位有效数字,超出的部分也会自动四舍五入
创建/删除表 create /drop table table_name
MariaDB [mysql]> create table joey_tbl( -> joey_id int not null auto_increment, -> joey_title varchar(100) not null, -> joey_author varchar(40) not null, -> submission_date date, -> primary key(joey_id) -> ); Query OK, 0 rows affected (0.023 sec)
插入数据 insert into table_name(field1,f2,f3...) values (values1,v2,v3...);
如果数据是字符型,必须使用单引号( ‘ )或者双引号( “ )
MariaDB [mysql]> insert into joey_tbl -> (joey_title,joey_author,submission_date) -> values -> ("joey","Eggy","3/28"); Query OK, 1 row affected (0.000 sec)
查询语句SELECT select _column,_column from _table [where Clause] [limit N][offset M]
**select * ** : 返回所有记录
limit N : 返回 N 条记录offset M : 跳过 M 条记录, 默认 M=0, 单独使用似乎不起作用limit N,M : 相当于 limit M offset N , 从第 N 条记录开始, 返回 M 条记录
MariaDB [mysql]> select * from joey_tbl; #读取数据表 +---------+------------+-------------+-----------------+ | joey_id | joey_title | joey_author | submission_date | +---------+------------+-------------+-----------------+ | 1 | joey | Eggy | 2020-03-28 | +---------+------------+-------------+-----------------+ 1 row in set (0.000 sec)
limit 应用 LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。初始记录行的偏移量是 0(而不是 1): 为了与 PostgreSQL 兼容,MySQL 也支持句法: LIMIT # OFFSET
mysql> SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15 //如果只给定一个参数,它表示返回最大的记录行数目: mysql> SELECT * FROM table LIMIT 5; //检索前 5 个记录行 //换句话说,LIMIT n 等价于 LIMIT 0,n。
WHERE子句 SELECT field1, field2,...fieldN FROM table_name1,table_name2... [WHERE condition1 [AND [OR]] condition2.....
查询语句中你可以使用一个或者多个表,表之间使用逗号**,** 分割,并使用WHERE语句来设定查询条件。
你可以在 WHERE 子句中指定任何条件。
你可以使用 AND 或者 OR 指定>=1个条件。
WHERE 可运用于 SQL 的 DELETE 或者 UPDATE 命令。
WHERE 类似于 if 条件,根据 MySQL 表中的字段值来读取指定的数据
MariaDB [mysql]> select * from joey_tbl where joey_title="JOEY"; +---------+------------+-------------+-----------------+ | joey_id | joey_title | joey_author | submission_date | +---------+------------+-------------+-----------------+ | 1 | joey | Eggy | 2000-03-28 | +---------+------------+-------------+-----------------+ 1 row in set (0.000 sec)
特殊条件 空值判断:is null
select * from joey_tbl where country is null; #查询joey_tbl表country列中的空值
between and
select * from joey_tbl where id between 1 and 5; #查询joey_tbl表中id列1到5的值
in
select * from joey_tbl where id in (1,3,5) #查询joey_tbl表id列等于1,3,5的值
更新/删除 UPDATE 用来修改或更新 MySQL 中的数据,我们可以使用 SQL UPDATE 命令来操作
#update 表名称 set 列名称=新值 where 更新条件; UPDATE table_name SET field1=new-value1, field2=new-value2 [WHERE clause]
MariaDB [mysql]> update joey_tbl set submission_date="2020-03-28" where joey_id=1; Query OK, 1 row affected (0.005 sec) Rows matched: 1 Changed: 1 Warnings: 0 select * from joey_tbl; +---------+------------+-------------+-----------------+ | joey_id | joey_title | joey_author | submission_date | +---------+------------+-------------+-----------------+ | 1 | joey | Eggy | 2020-03-28 | +---------+------------+-------------+-----------------+ 1 row in set (0.000 sec)
DELETE #DELETE FROM 表名称 where 删除条件; DELETE FROM table_name [WHERE Clause]
select * from joey_tbl; +---------+------------+-------------+-----------------+ | joey_id | joey_title | joey_author | submission_date | +---------+------------+-------------+-----------------+ | 1 | joey | Eggy | 2020-03-28 | +---------+------------+-------------+-----------------+ MariaDB [mysql]> DELETE from joey_tbl where joey_id=1; Query OK, 1 row affected (0.001 sec) MariaDB [mysql]> select * from joey_tbl; Empty set (0.000 sec)
LIKE子句 SELECT field1, field2,...fieldN FROM table_name WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'
%:多个字符
_ :1个字符
M%:模糊查询信息为M开头的
%M%:查询包含M的所有内容
%M_:查询
MariaDB [mysql]> select * from joey_tbl; +---------+------------+-------------+-----------------+ | joey_id | joey_title | joey_author | submission_date | +---------+------------+-------------+-----------------+ | 2 | JOEY | EGGY | 2022-03-28 | | 3 | JOEY | EGGY | 2022-03-28 | | 4 | JOEY | EGGY | 2022-03-28 | | 5 | JOEY | EGGY.com | 2022-03-28 | | 6 | JOEY | JOEY.com | 2022-03-28 | +---------+------------+-------------+-----------------+ 5 rows in set (0.000 sec) #SQL LIKE 子句中使用百分号 % 字符来表示任意字符 #如果没有使用百分号 %, LIKE 子句与等号 = 的效果是一样的 MariaDB [mysql]> select * from joey_tbl where joey_author like '%com'; +---------+------------+-------------+-----------------+ | joey_id | joey_title | joey_author | submission_date | +---------+------------+-------------+-----------------+ | 5 | JOEY | EGGY.com | 2022-03-28 | | 6 | JOEY | JOEY.com | 2022-03-28 | +---------+------------+-------------+-----------------+ 2 rows in set (0.000 sec)
UNION UNION 语句 :查询不同表中相同列中的数据(不包括重复数据)
ALL :返回所有结果(包括重复数据)
DISTINCT :删除重复数据(默认UNION已经删除了重复数据)
#这是"joey_game"表的数据 MariaDB [mysql]> select * from joey_game; +----+-------------------+-------+---------+ | id | name | value | country | +----+-------------------+-------+---------+ | 1 | Apex Legend | free | USA | | 2 | League of Legend | free | USA | | 3 | Rainbow six Siege | $30 | USA | +----+-------------------+-------+---------+ #这是"Eggy_game"表的数据 MariaDB [mysql]> select * from Eggy_game; +----+---------------------+-------+---------+ | id | name | value | country | +----+---------------------+-------+---------+ | 1 | Dying light | $40 | USA | | 2 | Oxygen Not Included | $30 | USA | | 3 | Elden Ring | free | USA | +----+---------------------+-------+---------+
#union MariaDB [mysql]> select value from joey_game -> union -> select value from Eggy_game -> order by value; +-------+ | value | +-------+ | $30 | | $40 | | free | +-------+ #union all MariaDB [mysql]> select value from joey_game -> union all -> select value from Eggy_game -> order by value; +-------+ | value | +-------+ | $30 | | $30 | | $40 | | free | | free | | free | +-------+
ORDER BY order by 就是对结果排序
select * from joey_game order by id asc,game desc #默认升序,asc可省,desc降序,不写明ASC DESC的时候,默认是ASC
ORDER BY 多列的时候,先按照第一个column name排序,在按照第二个column name排序
GROUP BY GROUP BY 用于将结果集根据指定的一个或多个列进行分组。常与聚合函数配合使用,以便对每组数据进行统计。
SELECT column1, aggregate_function(column2) FROM table_name WHERE condition GROUP BY column1;
#这个查询根据 country 列将客户分组,并统计每个国家的客户数量。 SELECT country, COUNT(*) AS customer_count FROM customers GROUP BY country;
按多个列分组 #此查询按 country 和 city 的组合进行分组,并计算每个国家和城市的客户数量 SELECT country, city, COUNT(*) AS customer_count FROM customers GROUP BY country, city;
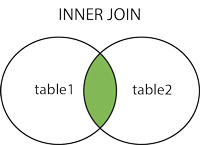
JOIN
INNER JOIN(内连接,或等值连接): 获取两个表中字段匹配关系的记录。LEFT JOIN(左连接): 获取左表所有记录,即使右表没有对应匹配的记录。RIGHT JOIN(右连接): 获取右表所有记录,即使左表没有对应匹配的记录。
INNER JOIN SELECT column1, column2, ... FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
测试实例数据 mysql> use RUNOOB; Database changed mysql> SELECT * FROM tcount_tbl; +---------------+--------------+ | runoob_author | runoob_count | +---------------+--------------+ | 菜鸟教程 | 10 | | RUNOOB.COM | 20 | | Google | 22 | +---------------+--------------+ 3 rows in set (0.01 sec) mysql> SELECT * from runoob_tbl; +-----------+---------------+---------------+-----------------+ | runoob_id | runoob_title | runoob_author | submission_date | +-----------+---------------+---------------+-----------------+ | 1 | 学习 PHP | 菜鸟教程 | 2017-04-12 | | 2 | 学习 MySQL | 菜鸟教程 | 2017-04-12 | | 3 | 学习 Java | RUNOOB.COM | 2015-05-01 | | 4 | 学习 Python | RUNOOB.COM | 2016-03-06 | | 5 | 学习 C | FK | 2017-04-05 | +-----------+---------------+---------------+-----------------+ 5 rows in set (0.01 sec)
#连接以上两张表来读取runoob_tbl表中所有runoob_author字段在tcount_tbl表对应的runoob_count字段值 mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a INNER JOIN tcount_tbl b ON a.runoob_author = b.runoob_author; +-------------+-----------------+----------------+ | a.runoob_id | a.runoob_author | b.runoob_count | +-------------+-----------------+----------------+ | 1 | 菜鸟教程 | 10 | | 2 | 菜鸟教程 | 10 | | 3 | RUNOOB.COM | 20 | | 4 | RUNOOB.COM | 20 | +-------------+-----------------+----------------+ 4 rows in set (0.00 sec)
LEFT JOIN LEFT JOIN 返回左表中的所有行,即使右表中没有匹配的行。如果右表没有匹配数据,结果中对应的列将显示 NULL。
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a LEFT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author; +-------------+-----------------+----------------+ | a.runoob_id | a.runoob_author | b.runoob_count | +-------------+-----------------+----------------+ | 1 | 菜鸟教程 | 10 | | 2 | 菜鸟教程 | 10 | | 3 | RUNOOB.COM | 20 | | 4 | RUNOOB.COM | 20 | | 5 | FK | NULL | +-------------+-----------------+----------------+ 5 rows in set (0.01 sec)
RIGHT JOIN RIGHT JOIN 会返回右表中的所有行,即使左表中没有匹配行。
mysql> SELECT a.runoob_id, a.runoob_author, b.runoob_count FROM runoob_tbl a RIGHT JOIN tcount_tbl b ON a.runoob_author = b.runoob_author; +-------------+-----------------+----------------+ | a.runoob_id | a.runoob_author | b.runoob_count | +-------------+-----------------+----------------+ | 1 | 菜鸟教程 | 10 | | 2 | 菜鸟教程 | 10 | | 3 | RUNOOB.COM | 20 | | 4 | RUNOOB.COM | 20 | | NULL | NULL | 22 | +-------------+-----------------+----------------+ 5 rows in set (0.01 sec)
ALTER ALTER 命令允许你添加、修改或删除数据库对象,并且可以用于更改表的列定义、添加约束、创建和删除索引等操作。
添加列 (ADD COLUMN) ALTER TABLE table_name ADD COLUMN new_column_name datatype;
删除列 (DROP COLUMN) ALTER TABLE table_name DROP COLUMN column_name;
修改列的数据类型 (MODIFY COLUMN) ALTER TABLE table_name MODIFY COLUMN column_name new_datatype;
修改列名 (CHANGE COLUMN) ALTER TABLE table_name CHANGE COLUMN old_column_name new_column_name datatype;
添加约束 (ADD CONSTRAINT) 可以使用 ALTER TABLE 来为表添加约束,例如 PRIMARY KEY、UNIQUE、FOREIGN KEY 等。
ALTER TABLE table_name ADD CONSTRAINT constraint_name constraint_type (column_name);
添加 PRIMARY KEY ALTER TABLE table_name ADD PRIMARY KEY (column_name);
添加 FOREIGN KEY ALTER TABLE child_table ADD CONSTRAINT fk_name FOREIGN KEY (column_name) REFERENCES parent_table (column_name);
修改表名 ALTER TABLE old_table_name RENAME TO new_table_name;
正则表达式 The REGEXP Operator
正则表达式速查表
量词
字符
含义
?
{0,1}
+
{1,}
*
{0,}
{n,m}
n-m次
{n,}
n次或更多
{n}
n次
预定义类
字符
等价类
.
[^\n]
\d
[0-9]
\s
[ \f\n\r\t\v]
\S
[^ \f\n\r\t\v]
\w
[a-zA-Z_0-9]
\W
[^a-zA-Z_0-9]
边界 并没有实际匹配任何字符,只是单纯匹配边界
字符
含义
^
开始
$
结尾
\b
单词开始或结束
\B
非单词开始或结束
#匹配地址中包含 “Trail” 的所有记录。 SELECT * FROM customers WHERE address REGEXP 'Trail';
#匹配地址中包含 “Trail” 或 “Avenue” 的记录。 SELECT * FROM customers WHERE address REGEXP 'Trail|Avenue';
INDEX 索引是一种数据结构,用于加快数据库查询的速度和性能。
创建索引 (CREATE INDEX) CREATE INDEX index_name ON table_name (column1, column2, ...);
唯一索引 (UNIQUE INDEX) # 唯一索引确保索引中的值是唯一的,不允许有重复值。 CREATE UNIQUE INDEX index_name ON table_name (column1, column2, ...);
唯一组合索引 #为多个列创建唯一索引,确保这些列的组合值在表中是唯一的。 CREATE UNIQUE INDEX idx_unique_customer ON customers (email, phone_number);
删除索引 (DROP INDEX) DROP INDEX index_name ON table_name;
创建组合索引(多列索引) #组合索引是指为多个列创建一个索引。组合索引可以加速针对多个列的查询。 CREATE INDEX index_name ON table_name (column1, column2);
显示索引信息 SHOW INDEXES FROM table_name;